The Search Engine Materializes
Having an index over Scheme source is no fun without a way to perform searches and present results in an human-friendly way. This weekend I therefore wrote a little web-servlet, which takes a query, looks up the terms in the index, and returns links to documents containing all terms.
It didn't take many searches to realize that I need to spend some time on 1) ranking the results and 2) supporting both case sensitive and case insensitive queries.
In general ranking is difficult to get right, hopefully the narrow scope of indexing Scheme source only will help. Managing Gigabytes explains ranking in details, and since I keep track of the term frequencies in the index, the ground work has been done.
Supporting both case sensitive and insensitive searches with the same index can be done with a little trick: after tokenizing all terms are converted to lower case before they are put in the index. When a search is made the query is likewise converted to lower case before a search is made. The returned document numbers can be used directly for a case insensitive search. To avoid false matches for a case sensitive search, the actual documents are retrieved from a repository and a simple minded search for the query terms are made.
This approach makes sense when indexes are large and the repository is available. My plan is put the index on a web-server without the repository, so instead I plan to make to indexes one for each type of search mode. Fortunately the code written so far is prepared for different indexes.
In lieu of an online web-servlet to try, I offer a screen shot:
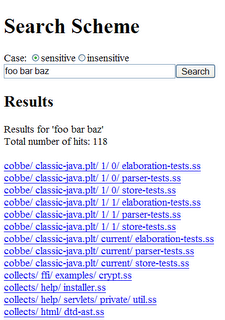
It didn't take many searches to realize that I need to spend some time on 1) ranking the results and 2) supporting both case sensitive and case insensitive queries.
In general ranking is difficult to get right, hopefully the narrow scope of indexing Scheme source only will help. Managing Gigabytes explains ranking in details, and since I keep track of the term frequencies in the index, the ground work has been done.
Supporting both case sensitive and insensitive searches with the same index can be done with a little trick: after tokenizing all terms are converted to lower case before they are put in the index. When a search is made the query is likewise converted to lower case before a search is made. The returned document numbers can be used directly for a case insensitive search. To avoid false matches for a case sensitive search, the actual documents are retrieved from a repository and a simple minded search for the query terms are made.
This approach makes sense when indexes are large and the repository is available. My plan is put the index on a web-server without the repository, so instead I plan to make to indexes one for each type of search mode. Fortunately the code written so far is prepared for different indexes.
In lieu of an online web-servlet to try, I offer a screen shot:
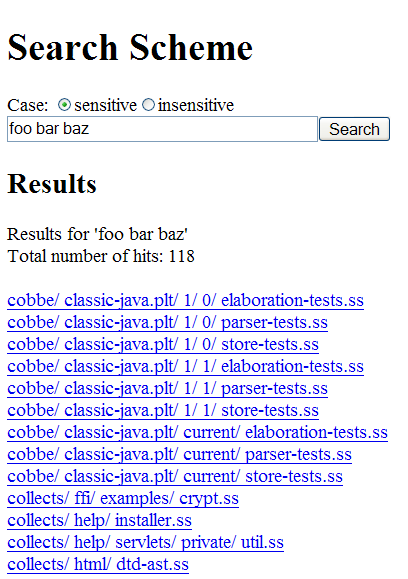
Labels: search engine

0 Comments:
Post a Comment
Links to this post:
Create a Link
<< Home